Machine Learning in SQL using BigQuery
A beginner's guide to training machine learning models with SQL using Google's BigQuery ML

I'm a Machine Learning Engineer passionate about building production-ready ML systems for the African market. With experience in TensorFlow, Keras, and Python-based workflows, I help teams bridge the gap between machine learning research and real-world deployment—especially on resource-constrained devices. I'm also a Google Developer Expert in AI. I regularly speak at tech conferences including PyCon Africa, DevFest Kampala, DevFest Nairobi and more and also write technical articles on AI/ML here.
Machine learning is a rapidly growing field that has seen a lot of interest from businesses and organizations. With the growing amount of data that businesses collect, it has become essential to use machine learning to extract insights from that data. One of the best tools for this is BigQuery, a fully managed, cloud-native data warehouse that makes it easy to analyze large amounts of data quickly. In this article, we will explore how to perform machine learning with SQL using BigQuery.
But before we start, it is essential to note that machine learning with SQL is not the same as traditional machine learning methods such as regression, clustering, or classification. Instead, it focuses on using SQL to analyze and transform data into the format required for machine learning. With that said, let's get started.
Setting up BigQuery
Before we start with machine learning, we need to set up BigQuery. If you haven't done this before, you can follow these simple steps:
Go to the BigQuery console and sign up for a Google Cloud account if you haven't already.
Create a new project or select an existing one.
Click on "Create Dataset" to create a new dataset to store your data.
Upload your data to the dataset using the "Create Table" button.
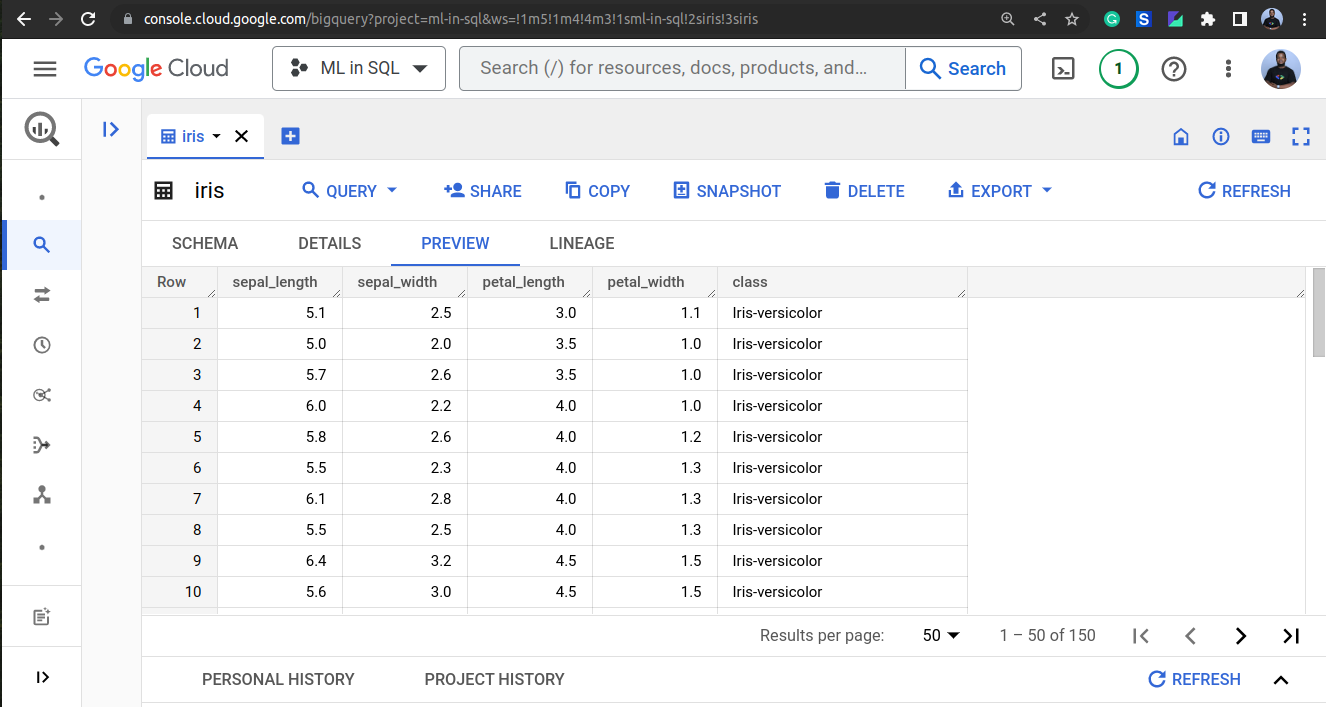
Explore the Data
Once you have uploaded your data, it is essential to understand it. In this tutorial, we will use the Iris dataset, which is a popular dataset for classification tasks. It contains 150 instances of three classes, with each class having 50 instances.
To explore the data, we can use SQL queries to select and visualize the data. The following code snippet shows how to select the first five rows of the dataset:
SELECT *
FROM `<project_id>.<dataset_id>.<table-name>`
LIMIT 5
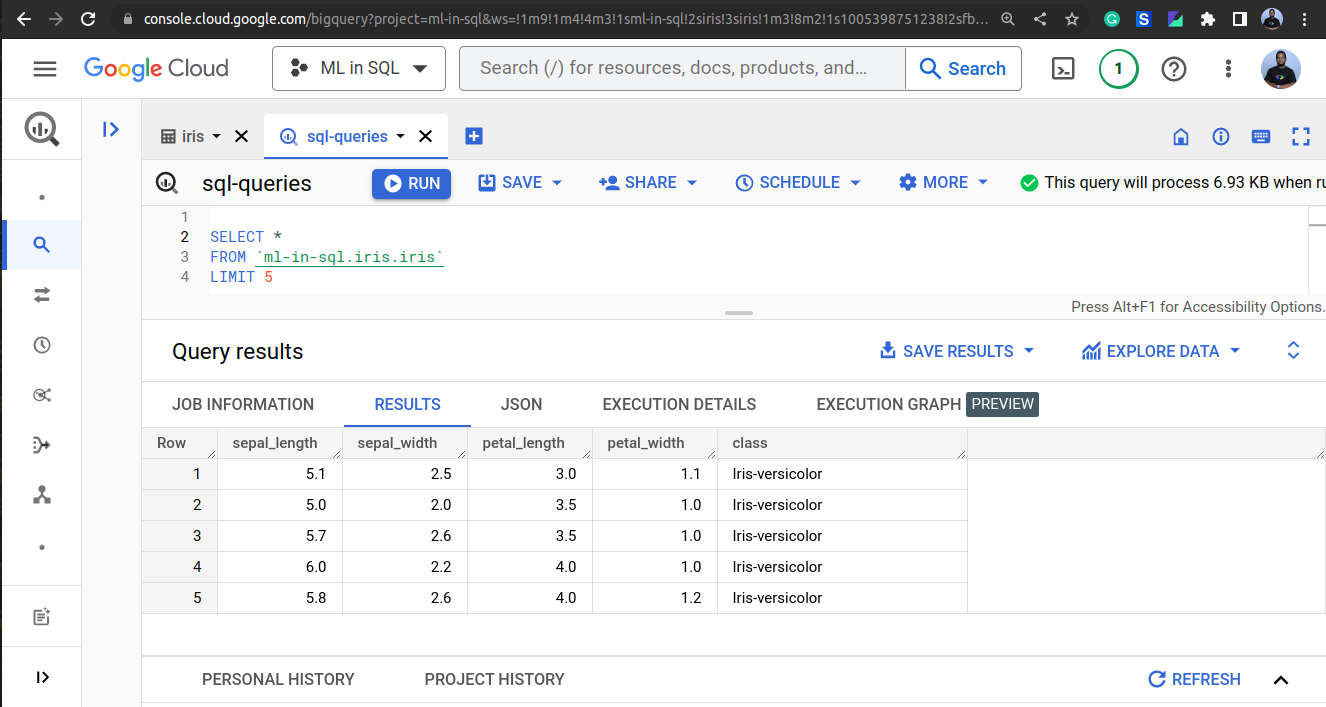
This will display the first five rows of the dataset. We can use the same query to select specific columns, such as the sepal length and sepal width:
SELECT sepal_length, sepal_width
FROM `<project_id>.<dataset_id>.iris`
LIMIT 5
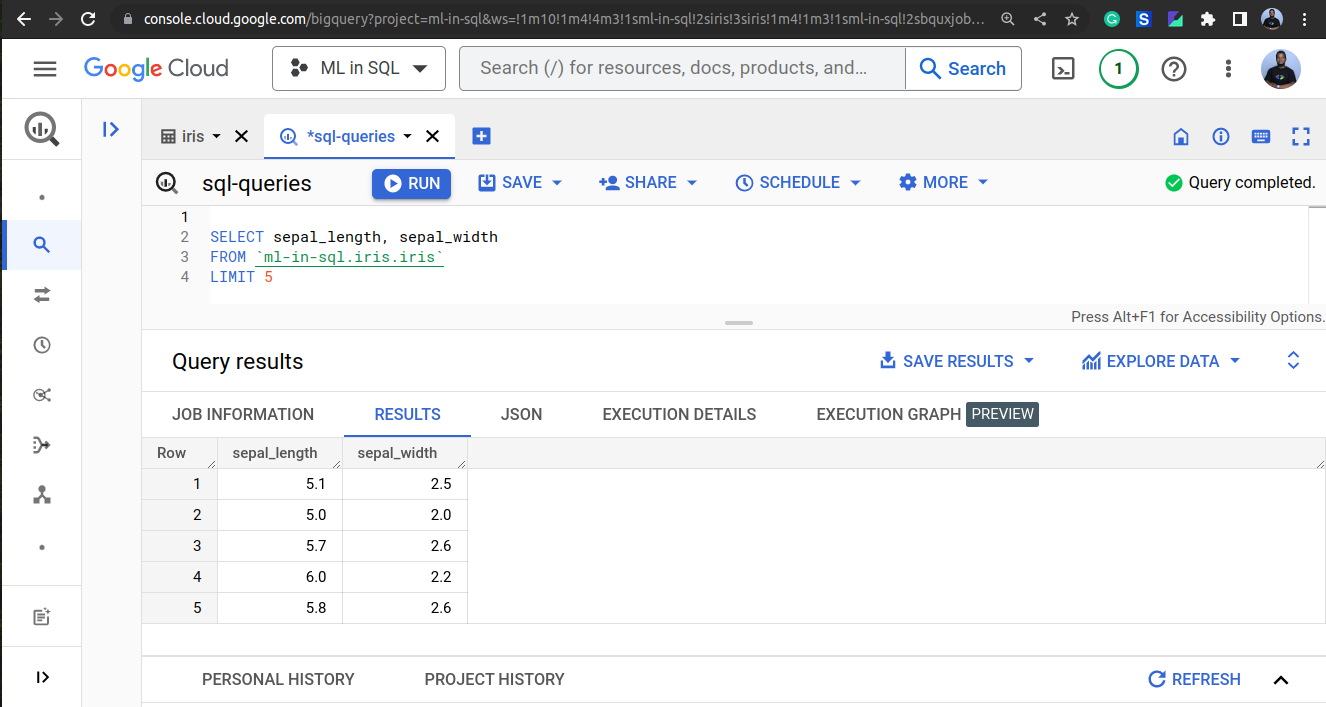
We can also use SQL to calculate summary statistics of the data, such as the mean and standard deviation:
SELECT
AVG(sepal_length) AS avg_sepal_length,
STDDEV(sepal_length) AS stddev_sepal_length
FROM `<project_id>.<dataset_id>.iris`
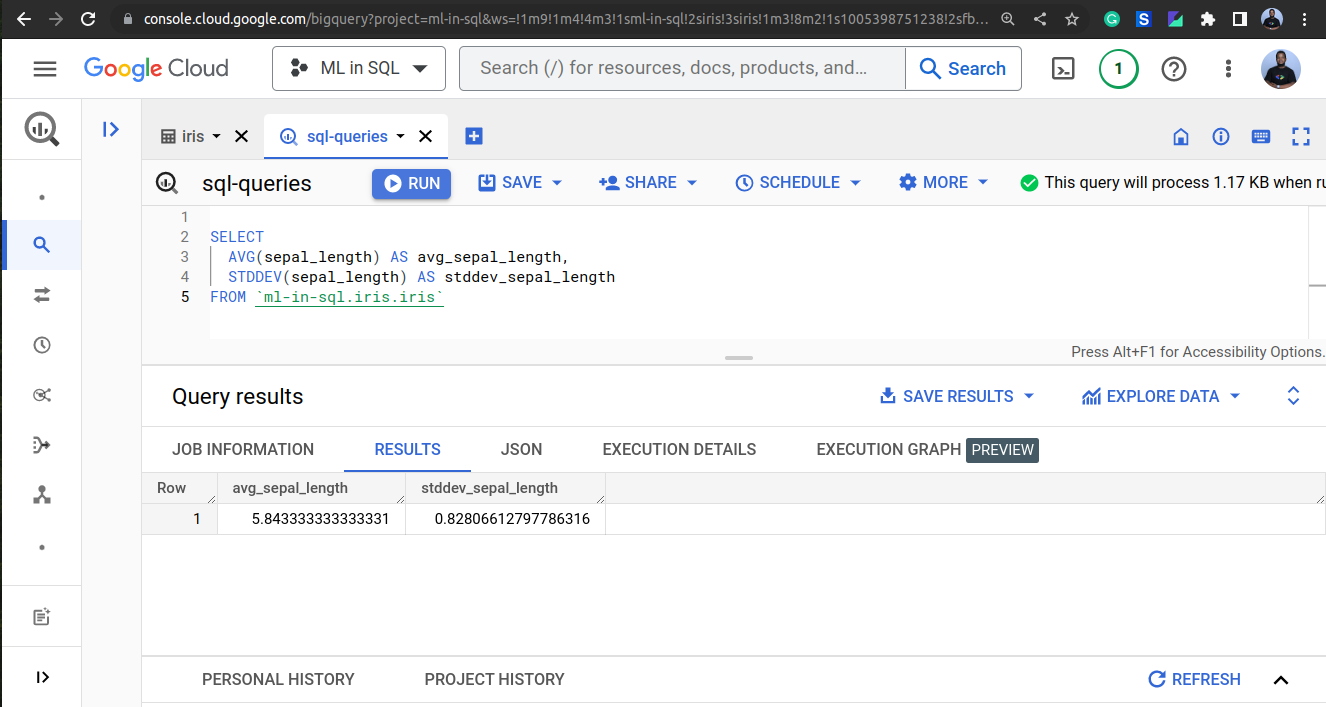
Transform the Data
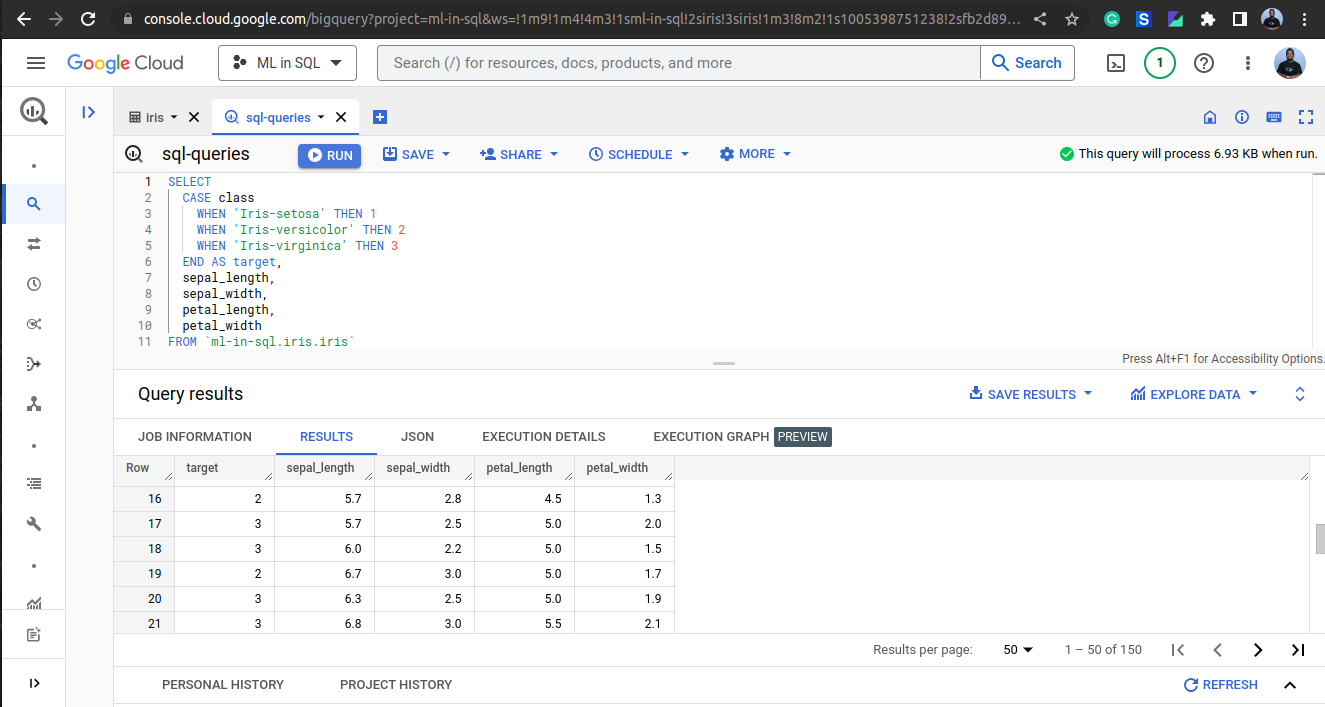
Before we can perform machine learning on the data, we need to transform it into the required format. In the case of the Iris dataset, we need to convert the categorical target variable into a numerical value. We can do this using a SQL CASE statement:
SELECT
CASE class
WHEN 'Iris-setosa' THEN 1
WHEN 'Iris-versicolor' THEN 2
WHEN 'Iris-virginica' THEN 3
END AS target,
sepal_length,
sepal_width,
petal_length,
petal_width
FROM `<project_id>.<dataset_id>.iris`
This query will create a new column called target with the numerical value of the class.
Train a Machine Learning Model
Now that we have transformed the data, we can train a machine learning model using SQL. In BigQuery, we can use the CREATE MODEL statement to create a model. In this tutorial, we will use logistic regression to classify the Iris dataset
To train a logistic regression model, we can use the following SQL query:
CREATE MODEL `<project_id>.<dataset_id>.iris_model`
OPTIONS
(model_type='logistic_reg',
input_label_cols=['target'],
max_iteration=50,
l1_reg=1,
l2_reg=0.1) AS
SELECT
CASE class
WHEN 'Iris-setosa' THEN 1
WHEN 'Iris-versicolor' THEN 2
WHEN 'Iris-virginica' THEN 3
END AS target,
sepal_length,
sepal_width,
petal_length,
petal_width
FROM `<project_id>.<dataset_id>.iris`
This query will create a new model called "iris_model" and train it using logistic regression. We can specify options such as the maximum number of iterations and regularization parameters.
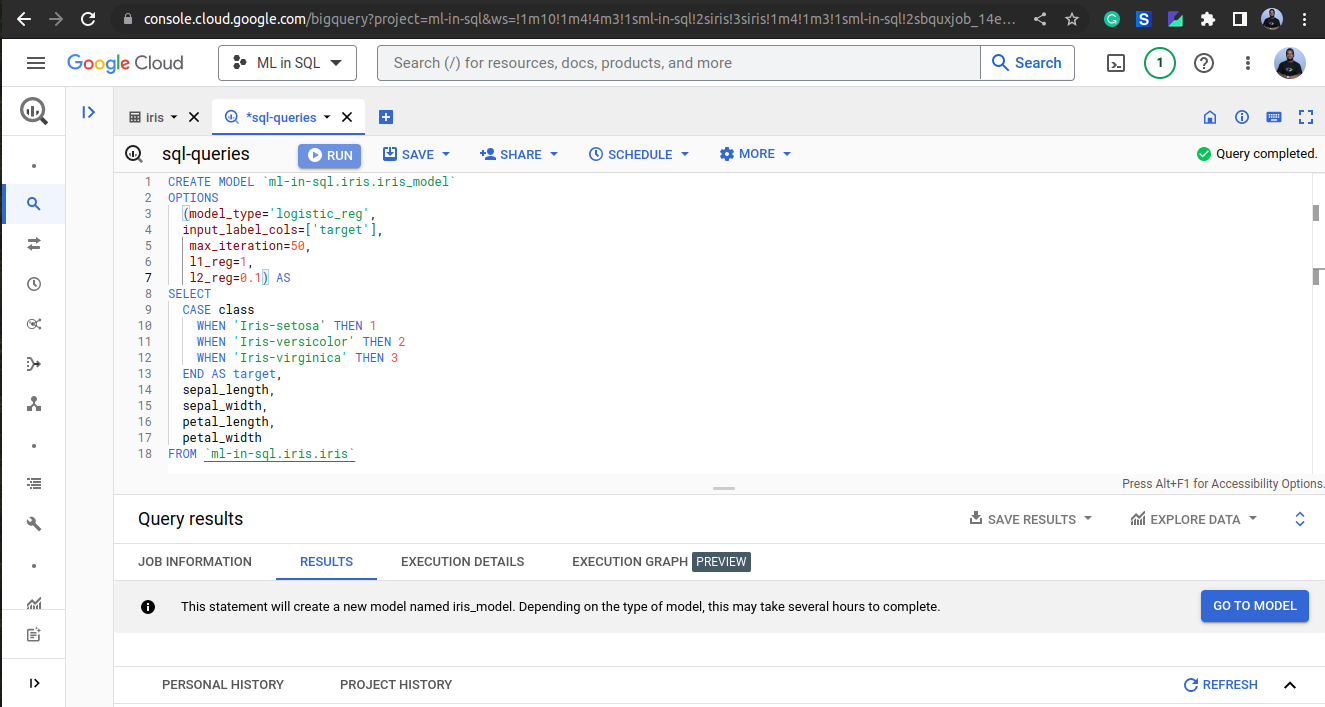
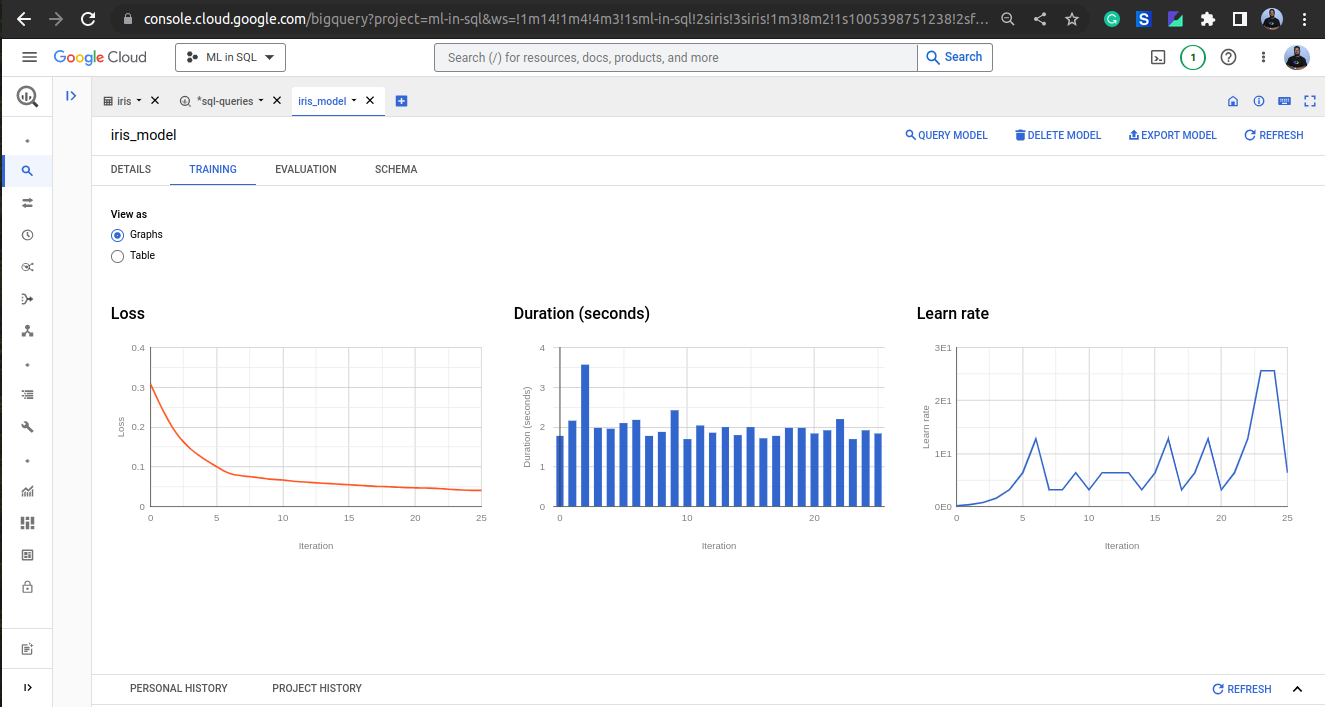
Click on GO TO MODEL button to see the training details of the model as shown below:
Evaluate the Model
Once the model is trained, we can evaluate its performance using SQL. In BigQuery, we can use the ML.EVALUATE function to evaluate the model. The following query shows how to evaluate the model on the training data:
SELECT
*
FROM ML.EVALUATE(MODEL `<project_id>.<dataset_id>.iris_model`,
(
SELECT
CASE species
WHEN 'Iris-setosa' THEN 1
WHEN 'Iris-versicolor' THEN 2
WHEN 'Iris-virginica' THEN 3
END AS target,
sepal_length,
sepal_width,
petal_length,
petal_width
FROM `<project_id>.<dataset_id>.iris`
))
This query will return metrics such as accuracy, precision, and recall.
Precision - 0.9534
Recall - 0.9533
Accuracy - 0.9533
F1 score - 0.9533
Log loss - 0.1231
ROC AUC - 0.9990

Make Predictions
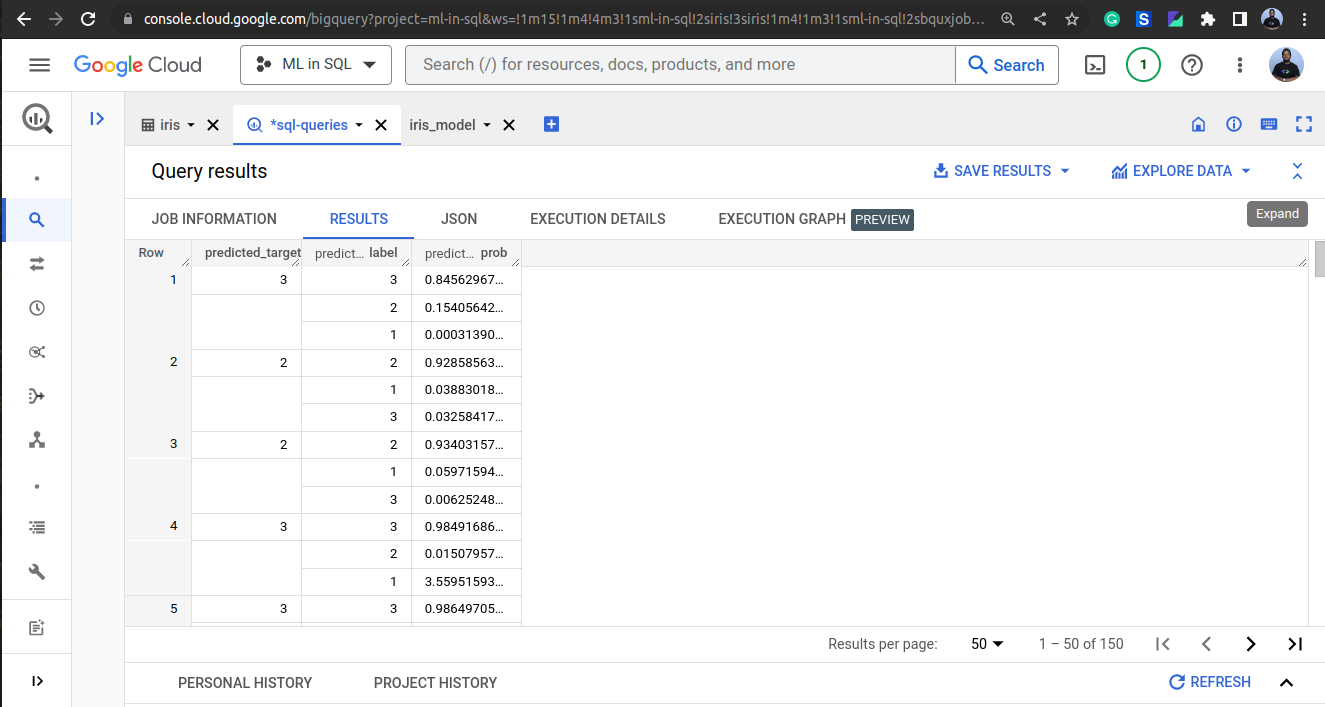
Finally, we can use the trained model to make predictions on new data. In BigQuery, we can use the ML.PREDICT function to make predictions. The following query shows how to make predictions on new data:
SELECT
predicted_target,
predicted_target_probs
FROM ML.PREDICT(MODEL `<project_id>.<dataset_id>.iris_model`,
(
SELECT
sepal_length,
sepal_width,
petal_length,
petal_width
FROM `<project_id>.<dataset_id>.new_data`
))
This query will return the predicted target value and the probability of each class for each row in the new data.
Conclusion
In this article, we have explored how to perform machine learning with SQL using BigQuery. We started by setting up BigQuery and exploring the data using SQL queries. We then transformed the data into the required format, trained a logistic regression model, and evaluated its performance. Finally, we made predictions on new data using the trained model. With BigQuery, it is possible to perform powerful machine learning tasks without leaving the SQL environment.




